


Microsoft połączył ChatGPT i Claude’a w jeden system, który w benchmarku pobił wszystkie dotychczasowe narzędzia badawcze oparte na jednym modelu.
- Microsoft wprowadził do Copilota dwa tryby wielomodelowe: Critique i Council, w których konkurencyjne modele AI nawzajem weryfikują swoją pracę, eliminując błędy.
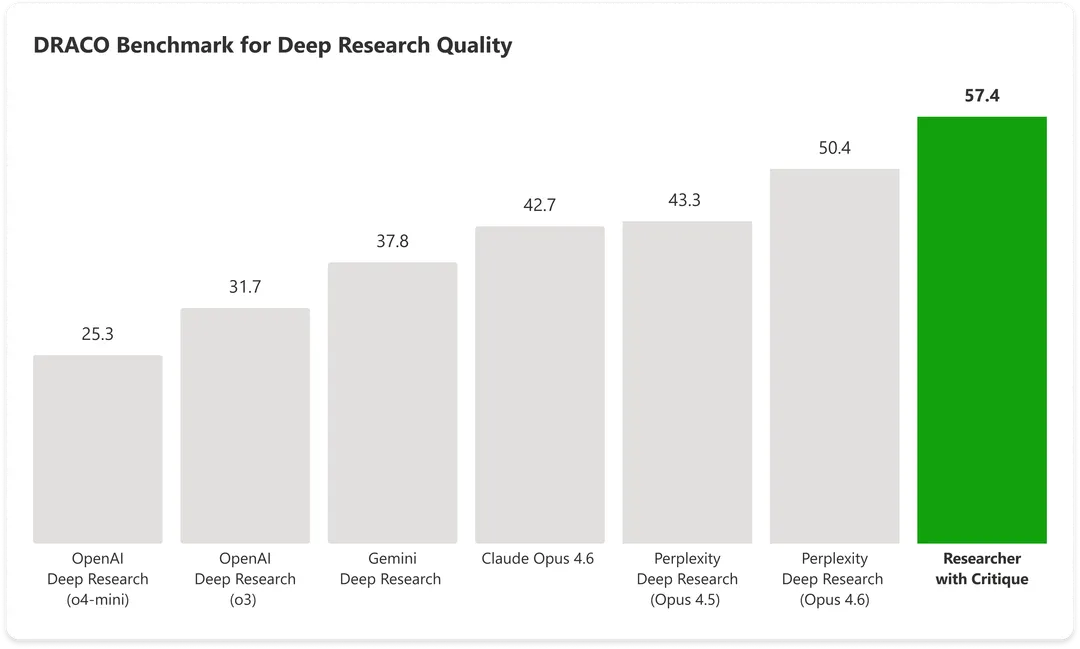
- System Critique uzyska wynik 57,4 pkt w benchmarku DRACO, przewyższając samodzielne rozwiązania OpenAI, Google, Perplexity i Anthropic.
- To dowodzi, że orkiestracja różnych LLM-ów daje wyniki lepsze, niż pojedynczy, najlepszy model.
Microsoft spróbował rozwiązać fundamentalny problem narzędzi AI typu deep research
Wszystkie dotychczasowe narzędzia “deep research” – od Google Gemini, aż po agentów badawczych od OpenAI czy Anthropic, działają według tego samego schematu.
Jeden model planuje zadanie, a następnie realizuje swój własny plan krok po kroku, przeszukując źródła i tworząc raport, który zwraca użytkownikowi.
Jako że w trakcie tego procesu nikt nie sprawdza, czy to, co robi LLM, jest w ogóle sensowne, efektem są halucynacje – błędne twierdzenia czy fałszywe cytowania, które użytkownik otrzymuje bez żadnego ostrzeżenia.
Microsoft słusznie zauważył, że brak weryfikacji jest słabością wszystkich narzędzi tego typu i postanowił odpowiedzieć prostym rozwiązaniem: rozdzieleniem generowania treści od jej oceny przy wykorzystaniu dwóch różnych modeli AI.
To Claude od Anthropic i ChatGPT od OpenAI, czyli produkty dwóch największych rywali, które Microsoft zaprzęgnął do pracy w trybie Critique, mającym odwzorowywać proces recenzji naukowej.
Cały cykl zaczyna się od powstania kompletnego szkicu, gdzie za zaplanowanie struktury raportu, zebranie materiałów źródłowych i stworzenie jego wstępnej wersji odpowiada ChatGPT.
Następnie dokument przesyłany jest do Claude’a, gdzie jest oceniany – Claude weryfikuje rzetelność faktów, jakość przywoływanych w raporcie źródeł czy trafność wnioskowania.
Oba modele wykorzystano także w drugim trybie – Council, gdzie pracują one równolegle nad tym samym zadaniem i tworzą dwie różne wersje raportów niezależnie od siebie.
Na końcowym etapie do gry wchodzi trzeci model, który analizuje oba opracowania, przygotowuje syntezę tych dwóch perspektyw, a użytkownik dowiaduje się, w których punktach dwa różne LLM-y doszły do sprzecznych wniosków.
Jak system radzi sobie praktyce? Microsoft przedstawił wyniki z benchmarka DRACO, który obejmuje 100 różnych zadań z 10 dziedzin, wśród których znajdziemy m.in. medycynę i prawo.
Działające w tandemie w trybie Critique modele GPT i Claude uzyskały w nim 57,4 pkt, co było wynikiem o 13,8% lepszym od dotychczasowego rekordu należącego do narzędzia Perplexity Deep Research wykorzystującego model Claude Opus 4,6.
Dla porównania działający samodzielnie Opus 4.6 otrzymał w nim 42,7 pkt, co sugeruje, że orkiestracja różnych modeli może dawać efekty przewyższające sumę ich indywidualnych możliwości.
Dostęp do nowych narzędzi Microsoftu wymaga udziału w programie Microsoft Frontier (early-access) oraz licencji Microsoft 365 Copilot.
Śledź CrypS. w Google News. Czytaj najważniejsze wiadomości bezpośrednio w Google! Obserwuj ->
Zajrzyj na nasz telegram i dołącz do Crypto. Society. Dołącz ->








