

Korzystając z LLM-ów, łatwo przypisać im cechy ludzkie takie jak intencja, zrozumienie czy nawet samoświadomość. Jednak to, co realnie dzieje się pod maską modeli językowych, jest z jednej strony – dużo prostsze, a z drugiej – dużo bardziej fascynujące, niż byśmy podejrzewali.
Spis treści:
Gra w przewidywanie słów
Zacznijmy od starej, szkolnej gry pt. „Wisielec”, która polegała na odgadywaniu jakiegoś słowa. Na początku widziałeś tylko puste pola reprezentujące litery, które to słowo tworzyło. Próbowałeś odgadnąć którąś z nich, a jeśli się pomyliłeś, na tablicy rysowano fragment szubienicy. Jeśli nie dałeś rady odgadnąć całego wyrazu przed narysowaniem przez Twojego przeciwnika całej szubienicy wraz z tytułowym „wisielcem”, przegrywałeś.
Zagrajmy w podobną grę, jednak zamiast jednego słowa masz odgadnąć całe zdanie. Na początku gry widzisz tylko cztery puste pola:
____ ____ ____ ____
Nie masz żadnych wskazówek, a liczba możliwych zdań jest astronomiczna.
Stolica ______ ____ _______
Pierwsze słowo, „stolica”, zawęża krąg poszukiwań, jednak niewystarczająco. Żeby jeszcze bardziej ograniczyć możliwe wybory, dodajmy kolejny wyraz:
Stolica Polski ____ ____
I kolejny, który czyni rozwiązanie banalnym:
Stolica Polski to ____
Odpowiedź to oczywiście „Warszawa”.
Teraz, zamiast trzech słów:
Dostaniemy ich jedenaście tak, by cały kontekst pozwolił nam na skuteczniejszą ____.
Jak zakończy się powyższe zdanie?
Czytając ten artykuł, wiesz, że odpowiedź to najprawdopodobniej „predykcję” lub „prognozę”. To dla Ciebie oczywiste, bo czytając cały tekst, masz dostęp do ponad 200 słów kontekstu. Przewidując słowa, nieświadomie korzystasz z prawdopodobieństwa warunkowego, które jest tym skuteczniejsze, im większym kontekstem dysponujesz. Każda kombinacja słów, które padły wcześniej, ogranicza zakres możliwych kontynuacji, aż w końcu prowadzi do kilku najbardziej prawdopodobnych opcji.
Jeśli wyobrazisz sobie, że:
-
Dostajesz ścianę tekstu złożoną np. z setek słów, mając za zadanie przewidzieć kolejne słowo w sekwencji.
-
Dokonujesz prognozy następnego słowa.
-
Wykorzystujesz dotychczasowy kontekst WRAZ ze swoją prognozą do kolejnej predykcji.
…wówczas intuicyjnie zrozumiesz, jak działa LLM.

Można przyjąć tu model z powyższego obrazka, w którym startujemy ze słowem „Adam” oraz kontekstem – ciągiem słów, które padły przed nim. Po prawej stronie widzimy dystrybucje prawdopodobieństwa. W pierwszej turze, na podstawie całego kontekstu wyliczamy, że najbardziej prawdopodobnym, następnym słowem będzie „nie” (0.75). „Doklejamy” więc słowo do kontekstu i znowu liczymy prawdopodobieństwo – tym razem na podstawie zaktualizowanego ciągu. Teraz, najbardziej prawdopodobną kontynuacją jest „może”. I tak dalej, aż krok po kroku wygenerujemy np. zdanie „Adam nie może zdjąć kurtki”.
Jednak między tym prostym przykładem (będącym wariacją na temat uproszczenia Marka Riedla z Georgia Tech) a tym, co realnie dzieje się pod maską modeli językowych, jest przepaść. Żeby spróbować ją choć minimalnie zasypać, trzeba zacząć od czegoś, co nazywa się „perceptronem”.
Perceptron, czyli najmniejszy kawałek wirtualnego „mózgu”
Zapomnijmy na chwilę o słowach i powiedzmy, że masz podjąć decyzję, czy pójść dziś wieczorem do baru. Wiesz, że wieczorem na pewno będzie padać i że mimo złej pogody będzie tam Twój najbliższy znajomy. Dodatkowo w okolicy nie znajdziesz żadnego przystanku, z którego będziesz mógł podjechać do miasta, a Twój samochód jest w warsztacie. To oznacza, że będziesz musiał iść tam na piechotę.
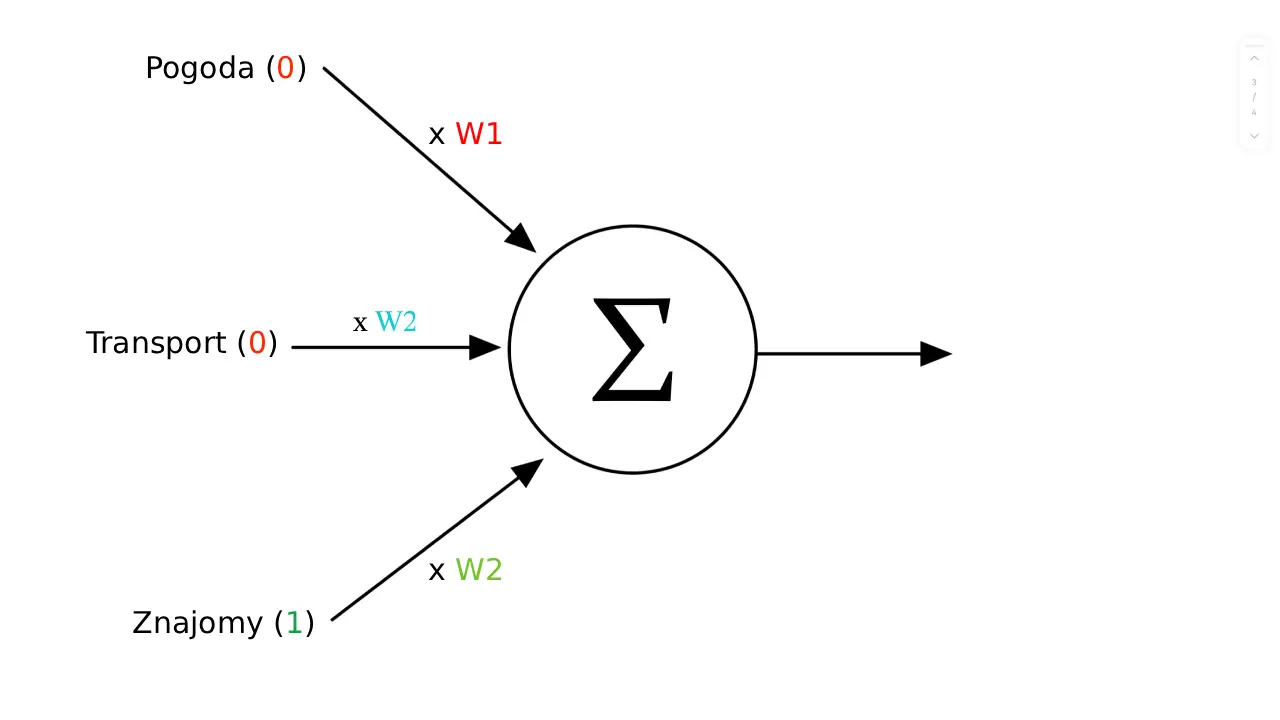
To trzy różne zmienne, które możemy zapisać w taki sposób (0 oznacza „NIE”, a 1 oznacza „TAK”):
-
dobra pogoda = 0
-
transport = 0
-
znajomy = 1
Teraz moglibyśmy stworzyć prosty model, w którym podejmiesz decyzję o wyjściu za każdym razem, gdy suma zmiennych przekroczy np. 1,5.
Czyli w tym przypadku postanowiłbyś zostać w domu, ponieważ 0 + 0 + 1 = 1.
To jednak podejście zbyt proste, ponieważ powyższe zmienne raczej nie będą dla Ciebie tak samo ważne.
To, że w barze będzie czekał na Ciebie znajomy, może być bardziej istotne niż brak transportu czy zła pogoda.
Do modelu dodamy więc wagi, które określą, jak ważna jest dla Ciebie każda z tych informacji. Niech dobra pogoda ma wagę 2, transport wagę 4, a obecność znajomego w barze wagę 6. Żeby podjąć decyzję, musimy jeszcze wiedzieć, jak bardzo chcesz pójść do baru, nie mając tych wszystkich informacji. To Twoja bazowa chęć, którą określimy jako „bias”.
Niech wyniesie -6, co oznacza, że domyślnie jesteś bardzo niechętny.
Mamy wszystkie informacje:
-
Dane wejściowe (pogoda, transport, obecność znajomego)
-
Wagi określające istotność każdej z danych wejściowych
-
Bias
Możemy więc podjąć decyzję, sumując wszystkie wartości wymnożone z wagami, a następnie dodając bias.
W tym przypadku wynik wyniósł równe 0, co oznacza, że Twoja decyzja to 1: wieczorem wyjdziesz do baru.
Idea uczenia maszynowego
Samodzielne podjęcie decyzji to nic trudnego, ponieważ sam z góry możesz ustalić wagi oraz bias. Co jednak jeśli masz przewidzieć decyzję człowieka, którego w ogóle nie znasz? Na początku, załóżmy że, dostajesz informacje o tysiącu różnych decyzji podjętych przez niego na podstawie różnych zmiennych.
Twoim zadaniem jest dostosować wagi tych zmiennych tak, by Twoje prognozy odzwierciedlały realne wyniki. Czyli musisz „wyciągnąć” z otrzymanych danych statystyki, które pozwolą Twoim prognozom zbliżyć się do realnie podjętych decyzji.
Na początku przypiszesz każdej zmiennej losową wagę i bias oraz wygenerujesz swoją prognozę.
Otrzymasz błąd – różnicę między Twoim „strzałem”, a realnym wynikiem i właśnie tu zaczyna się to, co nazywamy uczeniem maszynowym, ponieważ musisz zmodyfikować wagi i bias tak, by wyeliminować błędy (co ważne, w realnych sieciach neuronowych pracujących z rzeczywistymi danymi całkowite wyeliminowanie błędu może być niemożliwe, a celem uczenia jest sprowadzenie go nie do zera, a jak najbliżej zera).
W tym przypadku, jeśli będziemy kręcić „gałkami” wag jakiś czas, po iluś próbach otrzymamy takie, które będą generować predykcję 1 („TAK” – tj. człowiek wyszedł do baru) zawsze gdy np. zmienne a, b i c wynoszą 1. Okaże się, że nasz człowiek idzie do baru tylko wtedy, gdy np. ma transport, w barze czeka na niego znajomy i jest weekend.
Koniec końców proces wygląda tak: otrzymujemy dane wejściowe, przypisujemy wagi losowo, a następnie podczas wielu prób powoli staramy się zminimalizować błąd.
Przy tym celem jest tu nie wykucie danych na pamięć (co nazywa się przeuczeniem, z ang. overfitting), ale wyciągnięcie z nich informacji pozwalających na sensowne predykcje, czyli nabycie umiejętności generalizowania. Pozwoli ona modelowi zgadywać poprawnie po etapie treningu, kiedy dostanie dane, których nigdy wcześniej nie widział.
Jak działa prosta sieć neuronowa?
Mamy więc pojedynczy neuron, który przyjmuje dane wraz z ich wagami, a następnie przepuszcza wynik przez funkcję aktywacji. Sieć neuronowa, jak sama nazwa wskazuje, jest całą siecią takich neuronów.
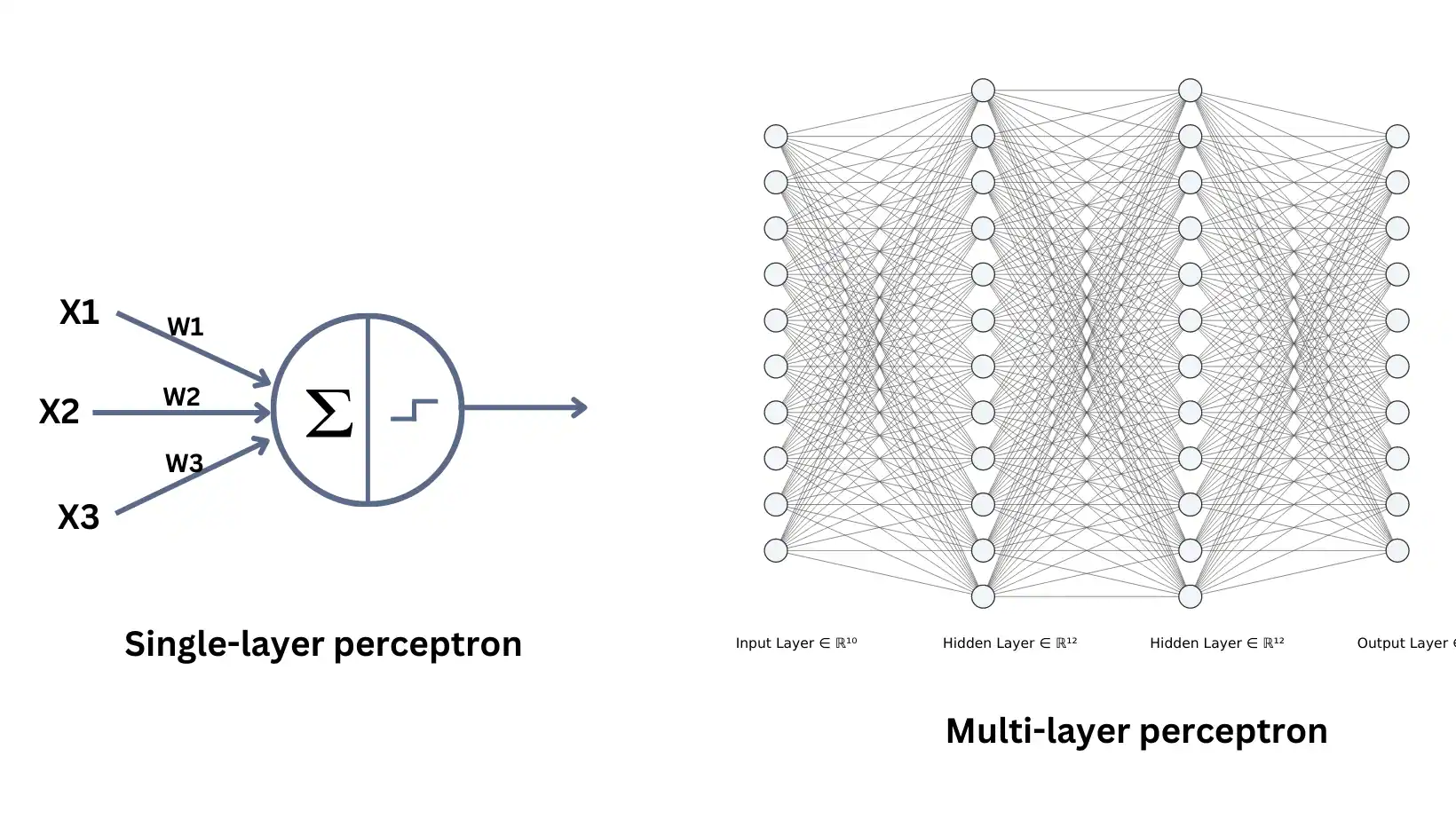
Po lewej widzimy przykład najprostszej, jednowarstwowej sieci neuronowej. Jest tu warstwa z danymi wejściowymi (x1, x2, x3…) wraz z ich wagami (w1, w2, w3…) oraz pojedynczy neuron, który wymnaża wartości z wagami, wszystko sumuje i zwraca 0 lub 1 – jak w naszym przykładzie – lub wartość między 0 a 1 (np. 0.72) określającą stopień aktywności neuronu.
Po prawej widać z kolei sieć wielowarstwową, składającą się z wielu takich neuronów. Tak jak po lewej mamy tu warstwę wejściową (Input Layer), jednak nie odsyła ona danych do jednego neuronu, a do wielu różnych neuronów składających się na tzw. warstwę ukrytą (Hidden Layer). Każdy z neuronów w tej warstwie robi dokładnie to samo: wymnaża wartości z wagami i aktywuje się lub nie, jednocześnie przekazując swój wynik (między 0 a 1) do każdego z neuronów w kolejnej warstwie ukrytej (przy czym warstw ukrytych może być dowolnie wiele).
Podczas treningu sieci sygnał przechodzi przez warstwy ukryte aż do Output Layer, czyli warstwy wyjściowej generującej ostateczną prognozę. Następnie sieć porównuje swoją prognozę z oczekiwanym wynikiem, liczy błąd i cofa się warstwa po warstwie, modyfikując wagi w taki sposób, by podczas następnej próby błąd był mniejszy.
Jak to działa w praktyce?
Łatwo zrozumieć to na klasycznym przykładzie z pismem odręcznym. Wyobraźmy sobie sieć, która ma rozpoznawać na skanach dokumentów pisane odręcznie cyfry. Mamy np. skan nabazgranej na kartce cyfry „8” wraz z etykietą, która mówi nam: „to jest ósemka”. Neurony oczywiście nie rozumieją, czym jest cyfra. Jak poradzić sobie z takim problemem?
Nasz obrazek ma 28×28 pikseli, dlatego zostaje podzielony na 784 piksele. Każdy z nich jest reprezentowany przez jedną liczbę w skali od 0 do 1, która określa jego kolor lub właściwie stopień zaczernienia. Tutaj 0 to idealna czerń, 0,5 to szarość, a 1 to biel. Każdy neuron z pierwszej warstwy ukrytej otrzyma wszystkie te liczby reprezentujące 784 piksele.

Dla uproszczenia możemy założyć, że podczas treningu neurony zaczną reprezentować poszczególne elementy obrazka. Powiedzmy, że neurony odpowiadające za piksele w zielonym prostokącie na powyższym obrazku świecą się, gdy mamy do czynienia z cyfrą 3, podczas gdy neurony z pomarańczowego prostokąta są wtedy w większości nieaktywne. Dopiero jednoczesna aktywacja obu tych grup daje cyfrę 8. Z kolei grupa oznaczona czerwonym prostokątem bierze udział w wielu różnych prognozach: jest aktywna, gdy na ekranie widać cyfry 2, 3, 5, 6, 7, 8, 9, 0, a nieaktywna przy cyfrach 1 i 4.
Pojedyncze grupki neuronów odpowiadają tutaj za określone elementy obrazu. Sieć nie rozumie samej cyfry, a statystyczne ramy, w których zamyka się konfiguracja pikseli, która przeważnie składa się na przedstawiający ją obraz. Pewien statystyczny archetyp ósemki.
W tym przypadku warstwa wyjściowa składa się z 10 różnych neuronów odpowiadających cyfrom od 0 do 9, a prognozą sieci jest ten neuron warstwy wyjściowej, który jest najbardziej aktywny. Cały proces treningu ma sprawić, by ścieżka aktywnych neuronów prowadziła właśnie do neuronu odpowiadającego cyfrze „8”.
I to się dzieje. Nie od razu, ponieważ początkowe wagi są całkiem losowe, ale po wielu próbach i dostosowaniach wag sieć „uczy się” wyglądu ósemki. Podczas długiego treningu nauczyła się, jakie neurony aktywują się najczęściej przy tej konkretnej cyfrze.
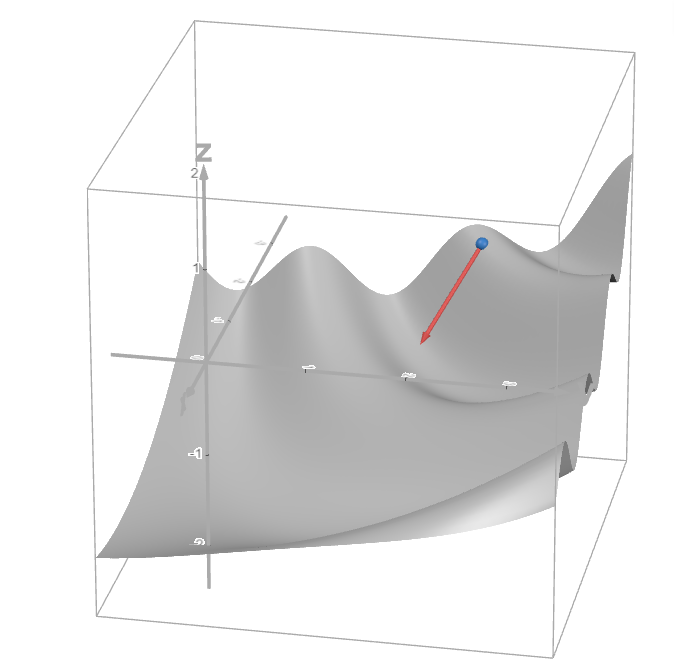
Cały proces treningu sieci neuronowej ma na celu zmniejszenie błędu tej sieci. Ze względu na ogromną liczbę wag jest to minimalizacja błędu w przestrzeniach o wymiarach, których nie jesteśmy w stanie sobie wyobrazić (w realnej sieci ta przestrzeń może mieć miliony lub miliardy wymiarów).
Jeśli dla uproszczenia przyjmiemy, że jest to przestrzeń 3D, funkcję kosztu można wyobrazić sobie jako wielką makietę górzystego terenu, a aktualny błąd jako kulkę wyrzuconą w losowym punkcie tej makiety. Kalkulacja nachylenia powierzchni w punkcie, w którym znajduje się kulka, pozwala modelowi „rozumieć”, w którym kierunku powinien korygować wagi tak, by zmniejszyć błąd i dostać się do którejś z dolin.
Transformery i LLM-y
LLM-y, czyli duże modele językowe takie, jak ChatGPT technicznie są właśnie sieciami neuronowymi. W praktyce ich powstanie wymagało jednak kolejnego przełomu.
W przykładzie z “wisielcem” z początku tekstu, jako człowiek – przewidywałeś słowa na podstawie długiego kontekstu. Z kolei w prymitywnych modelach NLP (Natural Language Processing, czyli przetwarzania języka naturalnego) – np. tych opartych na Łańcuchach Markowa “czytanie” tekstu odbywało się słowo po słowie, czyli predykcje modelu były uzależnione tylko od poprzedniego słowa.
Dlatego w zdaniu:
Stolicą Polski jest ___.
Puste miejsce zostałoby wypełnione na podstawie poprzedniego słowa w sekwencji – “jest”, przy czym model był całkowicie ślepy na wszystkie słowa, które pojawiły się wcześniej. Istniały także tzw. modele n-gramowe, gdzie prawdopodobieństwo następnego słowa w sekwencji zależało od n-słów (np. trzech czy pięciu poprzednich).
Następnie pojawiły się Rekurencyjne Sieci Neuronowe, które dostrzegały sąsiednie słowa, ale przy dłuższym tekście łatwo gubiły kontekst.
Mechanizm uwagi
Potrzebny przełom nastąpił w 2017 roku, gdy zespół badawczy Google’a opublikował badanie pt. “Attention Is All You Need”, które wprowadziło architekturę Transformerów z mechanizmem uwagi (Attention), pozwalającą modelowi na “widzenie” całego tekstu jednocześnie i dostosowywanie parametrów biorąc pod uwagę kontekst, w którym występuje dane słowo.
Konceptualnie można zrozumieć ten mechanizm na zasadzie uproszczenia z poniższego obrazka.
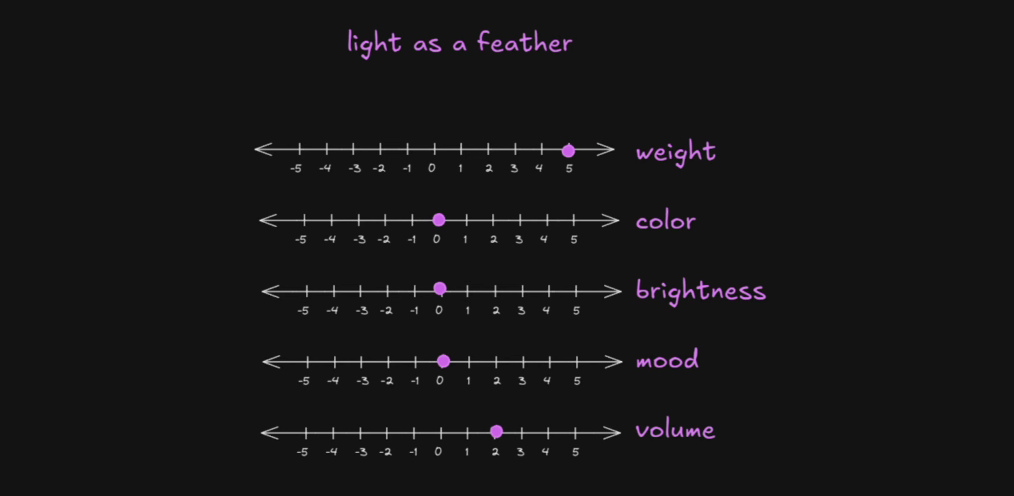
Tu słowo „light”, które w języku angielskim może oznaczać „światło”, ale i „lekkość” czy „jasność”, ma dostosowane wagi z uwagi na kontekst, w którym się znajduje. W tym przypadku fraza „light as a feather”, czyli „lekki jak piórko”, zwiększa wagę słowa „light” jako związanego z ciężarem. Attention pozwala więc tokenom „rozmawiać” ze sobą i dynamicznie modyfikować swoje wektory ze względu na otaczające słowa.
Czyli w transformerach wektor słowa zmienia się w zależności od zdania w którym to słowo się pojawia.
To klucz do tego, by model traktował ten sam wyraz (np. „zamek”) zupełnie inaczej w różnych kontekstach, odróżniając zamek błyskawiczny od zamku jako warowni otoczonej fosą.
Na przykład – jeśli mamy zdanie:
Zamek się zaciął, więc Adam nie mógł zdjąć kurtki
Słowo „zamek” wysyła zapytanie do wszystkich innych słów w sekwencji tak, by dokładnie określić swoje znaczenie.
Tutaj słowa „się”, „więc” i „Adam” dostają niską uwagę, ponieważ nie wnoszą nic do kontekstu potrzebnego do zrozumienia słowa „zamek”. Wysoką uwagę dostają z kolei słowa „zaciął” – jako słowo określające awarię mechaniczną oraz „kurtka” – jako część ubioru. Dzięki temu znaczenie „zamku” zostaje zaktualizowane z uwagi na słowa sąsiadujące i model „wie”, że mówi o zamku błyskawicznym, więc całkowicie wygasza znaczenie „zamku” jako średniowiecznej budowli.
Słowa w przestrzeni wielowymiarowej
I właśnie ta architektura jest podstawą dzisiejszych modeli LLM.
Na początku, podczas procesu tokenizacji, słowa z języka naturalnego są dzielone na tokeny: małe zbitki znaków. Następnie, w fazie zwanej embeddings, tym tokenom są przypisywane wartości liczbowe umieszczone w tzw. macierzy (to tzw. Embedding Matrix). Ciąg tych liczb to tzw. wektor. Każdy z tokenów ma właśnie taki wektor, będący w istocie ciągiem współrzędnych opisujących jego położenie w gigantycznej, wielowymiarowej przestrzeni.
Nie chcemy jednak tego komplikować, więc powiedzmy, że nie chodzi o tokeny, lecz o pełne słowa, oraz nie o przestrzeń o gigantycznej liczbie wymiarów, ale o trójwymiarową: taką, która będzie miała trzy współrzędne, np. [0.12, -0.59, 0.88].
Zdanie „Stolica Polski to Warszawa” zostaje więc rozbite na cztery różne słowa, przy czym każde z nich staje się unikalnym ciągiem trzech liczb, czyli wektorem.
Wszystkie słowa z danych treningowych zostają „wyrzucone” do przestrzeni 3D z losowo przypisanymi wektorami. Jako że wektory są losowe, słowo „zwierzę” sąsiaduje ze słowem „myśliwiec”, a obok znajdziemy też „zamrażarkę” czy „dywan”. Na tym etapie wyrazy nie mają ze sobą statystycznie żadnego związku. Zostanie on dopiero odkryty podczas treningu na tekście stworzonym przez człowieka, po którym słowa ułożą się w tej przestrzeni w sensowną strukturę powiązań.
W całej sieci pojedynczy neuron reprezentuje jakąś cechę lub cechy danego słowa, określone przez model podczas treningu.
Przykładowo może istnieć neuron, który odpowiada za powiązanie słowa „Trump” z innymi wyrazami często pojawiającymi się w kontekście politycznym, takimi jak „prezydent” czy „administracja”. Inny neuron aktywuje się wtedy, gdy słowo powinno zostać odmienione z uwagi na kontekst, na przykład w zdaniu: „Angela Merkel ugościła Donalda Trumpa”. Podczas procesu uczenia każde słowo przechodzi przez gęste warstwy takich neuronów, które modyfikują jego wektor na podstawie danych treningowych, co w praktyce oznacza zmianę jego położenia w przestrzeni.
Działa tutaj mechanizm podobny do tego z prostego perceptronu.
Model dostaje sekwencję, w której ma przewidzieć kolejną wartość, i generuje swoją predykcję poprzez wybór słowa o najwyższym prawdopodobieństwie wystąpienia. Następnie porównuje ją z rzeczywistym wynikiem. Liczy błąd między prognozą a realną wartością, czyli tak zwany koszt. Na koniec koryguje wagi wszystkich neuronów w procesie propagacji wstecznej tak, by następnym razem koszt był mniejszy.
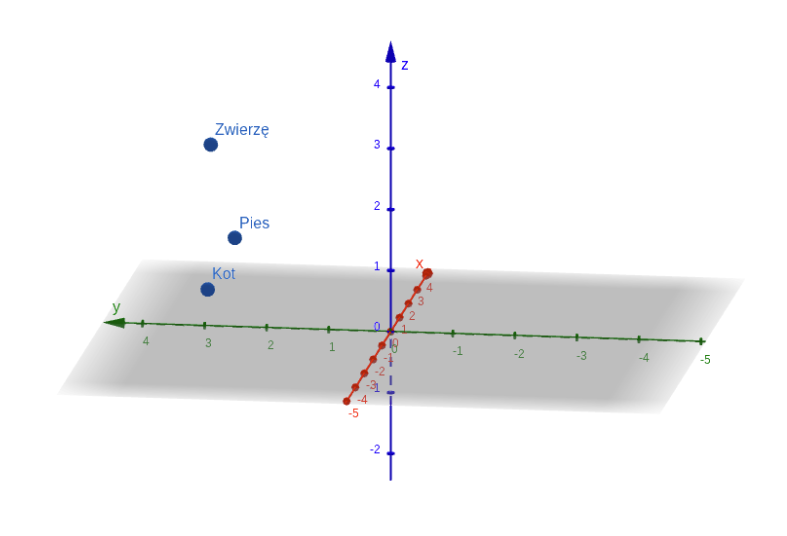
Powiedzmy, że po treningu takiego hipotetycznego modelu wektory słów „pies”, „kot” oraz „zwierzę” znajdują się dość blisko siebie, ponieważ w danych treningowych często były używane w podobnym kontekście. Co najciekawsze: jako że każde z tych słów jest reprezentowane przez wektor, może zostać wykorzystane w działaniu matematycznym.
Taki przykład po raz pierwszy pojawił się w pracy autorstwa Tomasa Mikolova i jego zespołu z Google’a pod tytułem „Efficient Estimation of Word Representations in Vector Space” z 2013 roku. Dowiedziono w niej, że jeśli w wytrenowanej sieci od wektora „Król” odejmiemy wektor „Mężczyzna” i dodamy do niego wektor „Kobieta”, wynik będzie mniej więcej odzwierciedlał wektor słowa „Królowa”. W ten sam sposób działają inne zależności, na przykład:
Paryż – Francja + Niemcy = Berlin
Maszyna nie rozumie oczywiście koncepcji monarchii czy stolicy państwa. Jednak podczas uczenia się na ogromnych zbiorach tekstu była zdolna do stworzenia pewnego zestawu zależności semantycznych, a przez to czegoś w rodzaju „modelu” naszej rzeczywistości opisanej za pomocą słów (należy jednak brać to określenie w cudzysłów, ponieważ LLM-y są krytykowane właśnie za brak wewnętrznego modelu świata przypominającego ludzki).
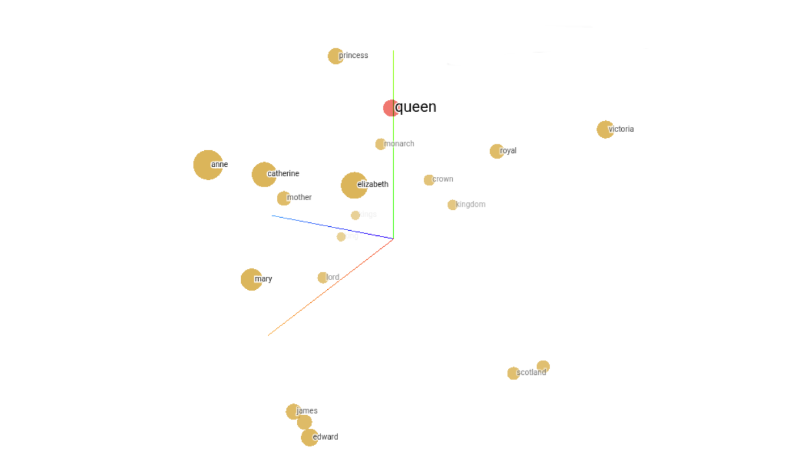
Widać to na realnym przykładzie z aplikacji Embedding Projector, gdzie najbliższe sąsiedztwo słowa „queen” obejmuje wyrazy takie jak „royal”, „crown” czy „king”.
„Black Box”
A więc tak w gigantycznym uproszczeniu działają modele LLM. Tyle wystarczyłoby, by trend antropomorfizacji tej technologii czy jeszcze bardziej niepokojący, tiktokowy trend „budzenia świadomości” ChataGPT nigdy nie powstały.
Skąd więc termin „Black Box” („czarne pudełko”), który często słyszy się w mediach?
Termin ten odnosi się do dwóch rzeczy: skali oraz emergencji, czyli powstawania cech całego systemu, których nie da się przewidzieć na podstawie cech pojedynczych jego elementów. W kwestii skali model LLM to statystyka o tak gigantycznej rozdzielczości, że z perspektywy człowieka jej „procesy myślowe” zlewają się w jednolitą masę. Zrozumienie tego, dlaczego model podjął taką, a nie inną decyzję, jest ekstremalnie trudne lub wręcz niemożliwe, ponieważ wynika ona z dostrojenia miliardów parametrów.
Sieć rozpoznająca odręcznie napisane cyfry (podstawowy przykład sieci neuronowej omawiany przez kanał 3Blue1Brown), mimo że wykonuje zadanie dla człowieka przeważnie banalne, ma 13 tysięcy parametrów (wag). Największy model językowy open source od Google’a, Gemma 3 27B, ma już 27 miliardów (!) parametrów. Trzeba więc pamiętać, że mamy do czynienia z dobrze znaną technologią, która w skali mikro jest przewidywalna, a jej nieprzewidywalność wynika ze skalowania. Jak powiedział Andrej Karpathy, były pracownik między innymi Tesli i OpenAI:
Tak naprawdę rozumiemy architekturę z pełnymi detalami. Wiemy dokładnie, jakie operacje matematyczne mają miejsce na każdym etapie. Problem w tym, że te 100 miliardów parametrów [liczba parametrów oczywiście różni się między modelami] jest rozproszonych po całej sieci neuronowej. Wiemy, jak manipulować parametrami, by uczynić całą sieć lepszą w zadaniu prognozowania następnego słowa, ale tak naprawdę nie wiemy, co te 100 miliardów parametrów robi. Możemy zmierzyć, że lepiej prognozuje następne słowo, ale nie wiemy, jak te parametry współpracują, by faktycznie tak działać.
Wszystko to składa się na fascynującą technologię, która jednak ma zaskakująco niewiele wspólnego z medialnymi fantazjami o świadomej AI. Technologię, która jest omylna i ma tendencje do tzw. halucynacji – generowania sprzecznych z faktami treści, które model tworzy nie dlatego, że „uważa” je za prawdziwe, lecz dlatego, że… były statystycznie prawdopodobne.
Śledź CrypS. w Google News. Czytaj najważniejsze wiadomości bezpośrednio w Google! Obserwuj ->
Zajrzyj na nasz telegram i dołącz do Crypto. Society. Dołącz ->








