

AI powoli staje się nieodłączną częścią pracy grafików, twórców gier, marketerów i wszystkich tych, którzy potrzebują szybkich wizualizacji. Postanowiliśmy więc przetestować 11 z popularnych modeli generatywnej sztucznej inteligencji, oceniając je w kilku różnych kategoriach po to, by wyłonić najlepszą trójkę, jak i modele najlepiej sprawdzające się w specyficznych zadaniach.
Spis treści:
Najlepsze AI do generowania grafik | Ranking 2025
🥇 1. Gemini 2.5 Flash Image (Nano Banana): 7,7 | Najlepszy do edycji
🥈 2. Midjourney : 7,5 | Najlepszy do ilustracji i realizmu
🥉 3. Flux.1 Kontext Max: 7,3
📄 Najlepszy do grafik z tekstem: Ideogram v3
👑 Uniwersalna trójka generatywnych modeli AI
Gdybyśmy mieli wskazać trzy narzędzia, które razem złożą się na zestaw, który poradzi sobie w większości przypadków, byłyby to:
- Midjourney: do generowania zdjęć i ilustracji
- Ideogram v3: do generowania grafik uwzględniających tekst
- Gemini 2.5 Flash Image (Nano Banana): do edycji grafik stworzonych przez dwa poprzednie modele
Jak testowaliśmy generatory obrazów AI?
Do testów zebraliśmy 11 różnych modeli GAI:
- Midjourney
- Nano Banana
- DALL-E 3
- Juggernaut XL (Open Source)
- Flux Kontext Max
- Stable Diffusion SD3 (Open Source)
- Adobe Firefly
- Ideogram
- Leonardo AI
- Canva AI
- HiDream-l1 (Open Source)
Przed ich rozpoczęciem zakładaliśmy, że nie istnieje jedno “najlepsze” narzędzie AI do generowania grafik – każde z nich ma swoje mocne strony i ograniczenia, tak więc wybór tego jednego zależy od naszych potrzeb. Dlatego aby ocenić jakość zwracanych treści, przygotowaliśmy kilka pojedynczych testów, w których modele wygenerowały:
- Minimalistyczne logo fikcyjnej firmy – uwzględniające tekst.
- Realistyczne zdjęcie produktu.
- Realistyczne zdjęcie człowieka.
- Typową ilustrację sztuki cyfrowej.
- Dwie grafiki koncepcyjne przedstawiające postać oraz lokację z gry wideo.
Jednocześnie, każda AI miała kilka szans na wygenerowanie jak najlepszej treści, przy czym w ocenie braliśmy pod uwagę m.in. często powtarzające się błędy – nawet, jeśli nie były one obecne w najlepszym obrazie, jaki zdołał wygenerować model.
To jednak nie wszystko, ponieważ w zestawieniu znalazły się dwa modele konkurujące ze sobą jako narzędzia do edycji grafik i ich syntezy w nowe treści – Nano Banana oraz Flux Kontext Max. Czekały je więc kolejne próby, wykorzystujące najlepsze grafiki wygenerowane podczas wcześniejszych etapów.
W tym, dodatkowym teście, modele:
- Umieściły dwie postaci z osobnych grafik obok siebie na jednym zdjęciu oraz zmodyfikowały ich wygląd.
- Umieściły logo oraz tekst na t-shirtach postaci.
- Umieściły logo na produkcie i stworzyły przykładowe grafiki e-commerce z hasłem reklamowym.
Podczas testów korzystaliśmy z OpenArt (openart.ai) – platformy, która pozwala nam generować grafiki z wykorzystaniem ponad 100 modeli AI. Na platformie znajdziemy 7 z 11 testowanych narzędzi, przy czym tylko jeden z tych, które nie są na niej dostępne – Midjourney, świetnie poradził sobie w testach.
Do wygenerowania wszystkich grafik do testów (w artykule znalazły się tylko przykłady obrazów wysokiej i niskiej jakości), wykorzystaliśmy całe 4000 tokenów z planu Essential (14$ w planie miesięcznym). Tutaj znajdziesz pełen cennik (aktualnie dostępne spore zniżki za plan roczny): https://openart.ai/pricing.
Jak pisać lepsze prompty dla modeli AI? Przykłady z testów
Zanim przejdziemy do testowania poszczególnych modeli AI, wyjaśnimy w jaki sposób budowaliśmy prompty do tych testów.
Wszystkie są w języku angielskim – dla bardziej precyzyjnych rezultatów (modele są trenowane na anglojęzycznych opisach). W niektórych przypadkach były one też dosyć długie, zawierając jak najwięcej potrzebnych detali. Każdy z nich wpisywał się w formułę:
[ROLA, KTÓRĄ MA PRZYJĄĆ MODEL] + [TREŚĆ GRAFIKI Z DETALAMI] + [DODATKOWE INFORMACJE O STYLU]
Na przykład:
[“as a Comic Digital Artist…” ] + [ “create cyberpunk character in a futuristic city centre…”] + [“sharp linework, intricate details, cinematic lighting …”]
W gruncie rzeczy jest to sposób pisania promptów, który powinien dawać najlepsze efekty.
Skorzystaliśmy z niego także podczas generowania okładki dla tego artykułu.
Większość pracy wykonał tu Ideogram v3, a polecenie dla niego wpisywało się w powyższy szablon, uwzględniając detale dotyczące pozycjonowania tekstu:
[“as an e-commerce graphic artist“] + [“create a professional looking ecommerce illustration by adding big text in the column on the left side of the image: [text1: „RANKING MODELI AI”], [text2: „Test 11 narzędzi!”]”] + [“text1 and text2 should have different dark colors. The text should be distinctive and clearly visible.”]
Jak widać, poprosiliśmy model o tekst po lewej stronie obrazu, w kolumnie, oraz podzieliliśmy go na dwie części: [text1: …] oraz [text2: …]. W ten sposób, AI powinna doskonale wiedzieć, czego oczekujemy.
Z reguły, im więcej takich szczegółowych poleceń zawiera prompt, tym lepszą grafikę otrzymamy.
Negative prompt i seed
Jeśli chodzi o prompt, warto wspomnieć też o dwóch ważnych zagadnieniach.
Pierwszym z nich jest tzw. Negative prompt, czyli instrukcja dla modelu AI, mówiąca, czego ten ma NIE generować. Taka instrukcja ma postać listy i zwykle wkleja się ją do okienka „negative prompt” na danej platformie. Przykładem modelu, w którym takiego okienka nie mamy jest Midjourney. Tutaj, negative prompt jest taką samą listą, tyle że z przedrostkiem „–no”:
/imagine some random image –no people, animals, cars, bikes
W rezultacie otrzymamy od Midjourney przypadkowy obraz („some random image”) nieuwzględniający elementów z listy. To komenda przydatna w przypadku, w którym model generuje na grafikach obiekty, których nie chcielibyśmy tam widzieć.
By zrozumieć zagadnienie drugie – seed (z ang. „ziarno”), trzeba wiedzieć, że każde generowanie grafiki przez model AI rozpoczyna się od obrazu zawierającego losowy szum. Można wyobrazić go sobie jako szum telewizyjny. Seed to po prostu liczba przypisana do konkretnego wzorca szumu, od którego model rozpoczął tworzenie jednego, konkretnego obrazu.
Jeśli seed danej grafiki wynosi, dla przykładu – „1234”, dokładnie ten sam prompt zastosowany przy seedzie „4321” będzie wyglądał inaczej. I odwrotnie – ten sam prompt plus ten sam seed przeważnie powinny wygenerować identyczny obraz.
To istotne dla powtarzalności generowanych grafik. Jeśli model stworzył obraz, który stylistycznie nam się podoba, możemy skopiować seed, który znajdziemy w jego parametrach, a następnie wygenerować nową grafikę z tym seedem – na podstawie lekko zmodyfikowanego promptu. Dzięki temu mamy szansę na otrzymanie innego obrazu, ale utrzymanego w podobnej estetyce.
Niektóre modele mają pola przeznaczone do ustawiania seeda. Midjourney w wersji z Discorda, z którego korzystaliśmy, pozwala na jego ustawienie obok normalnego promptu – w taki sposób:
/imagine prompt: a futuristic city at sunset –-seed 12345

Dla przykładu – przy okazji generowania w Midjourney obu powyższych grafik, skorzystaliśmy z tego samego, losowego seeda („12345”) i promptu, który różnił się tylko opisem okrętu, który miał pojawić się na grafice („ship” vs „container ship”).
Po wyjaśnieniu promptów, pora sprawdzić, jak popularne modele AI poradziły sobie z naszymi zadaniami!
Testujemy 11 modeli AI do generowania grafik
Test 1. Logo
Na pierwszym etapie, każdy z modeli utworzył proste, minimalistyczne logo fikcyjnej pizzerii, na podstawie polecenia:
As a professional logo designer, create a minimalistic logo design of pizza restaurant with the word 'TEST LOGO: made for the sake of testing’ below, colors: red, yellow, white, on black background
Test obnażył mankamenty niektórych z modeli – nietrzymanie się promptu wpisanego przez użytkownika oraz problemy w pracy z tekstem.
Ten pierwszy błąd popełnił Midjourney, ignorując część tekstu, który miał znaleźć się na obrazie.
Częstym błędem były halucynacje i generowanie pod logo kompletnie niezrozumiałego lub niekompletnego tekstu (DALL-E, Juggernaut XL, SD3, Adobe Firefly, Leonardo, HiDream-l1), jednak przy zauważeniu takich pomyłek, w ostateczności braliśmy także pod uwagę kwestie czysto estetyczne (w niektórych przypadkach logo. z wyłączeniem tekstu, było niezłej jakości).
Tę konkurencję ex aeuqo wygrały modele Flux Kontext Max oraz Ideogram – obie otrzymały ocenę 9.
| Model | Ocena |
| Midjourney | 4 |
| Nano Banana | 6 |
| DALL-E 3 | 4 |
| Juggernaut XL | 3 |
| Flux Kontext Max | 9 |
| Stable Diffusion SD3 | 3 |
| Adobe Firefly | 4 |
| Ideogram | 9 |
| Leonardo AI | 6 |
| Canva AI | 7 |
| HiDream-I1 | 3 |
Test 2. Realistyczne zdjęcie produktu
Kolejne zadanie jest już nieco prostsze. Wygenerowanie zdjęcia produktu, przy czym “produkt” to tutaj fioletowa puszka z napojem gazowanym na białym tle:
As a professional product photographer, create an ultra-realistic photo of a clearly visible dark purple soda can with yellow edges, clean white background, sharp details, high-resolution, photorealistic lighting and reflections, realistic shadows, studio photography style, ; no text, no letters, no watermark.

Aż 3 modele otrzymały tutaj ocenę 8. Główne problemy tych, które nie poradziły sobie najlepiej, polegały na ignorowaniu listy rzeczy, których NIE chcemy na zdjęciu i umieszczaniu tekstu na puszce oraz generowaniu czegoś, co bardziej, niż zdjęcie, przypominało mniej lub bardziej prymitywny render 3D.

| Model | Ocena |
| Midjourney | 7 |
| Nano Banana | 8 |
| DALL-E 3 | 5 |
| Juggernaut XL | 3 |
| Flux Kontext Max | 8 |
| Stable Diffusion SD3 | 5 |
| Adobe Firefly | 8 |
| Ideogram | 6 |
| Leonardo AI | 6 |
| Canva AI | 7 |
| HiDream-I1 | 3 |
Test 3. Realistyczne zdjęcie twarzy
Następnie każdy model został poproszony o stworzenie realistycznego zdjęcia uśmiechającej się kobiety w centrum miasta:
As a professional photographer, create an ultra-realistic photo of a smiling young woman made in the city centre, freckles, soft skin texture, natural daylight, natural skin lighting, people and restaurants in the background, realistic anatomy, natural pose, shallow depth of field, 85mm lens photography
W tym przypadku, dwa modele – Midjourney oraz Juggernaut XL zdeklasowały konkurencję produkując coś, co faktycznie można pomylić z realnymi zdjęciami (szczególnie w przypadku Midjourney).
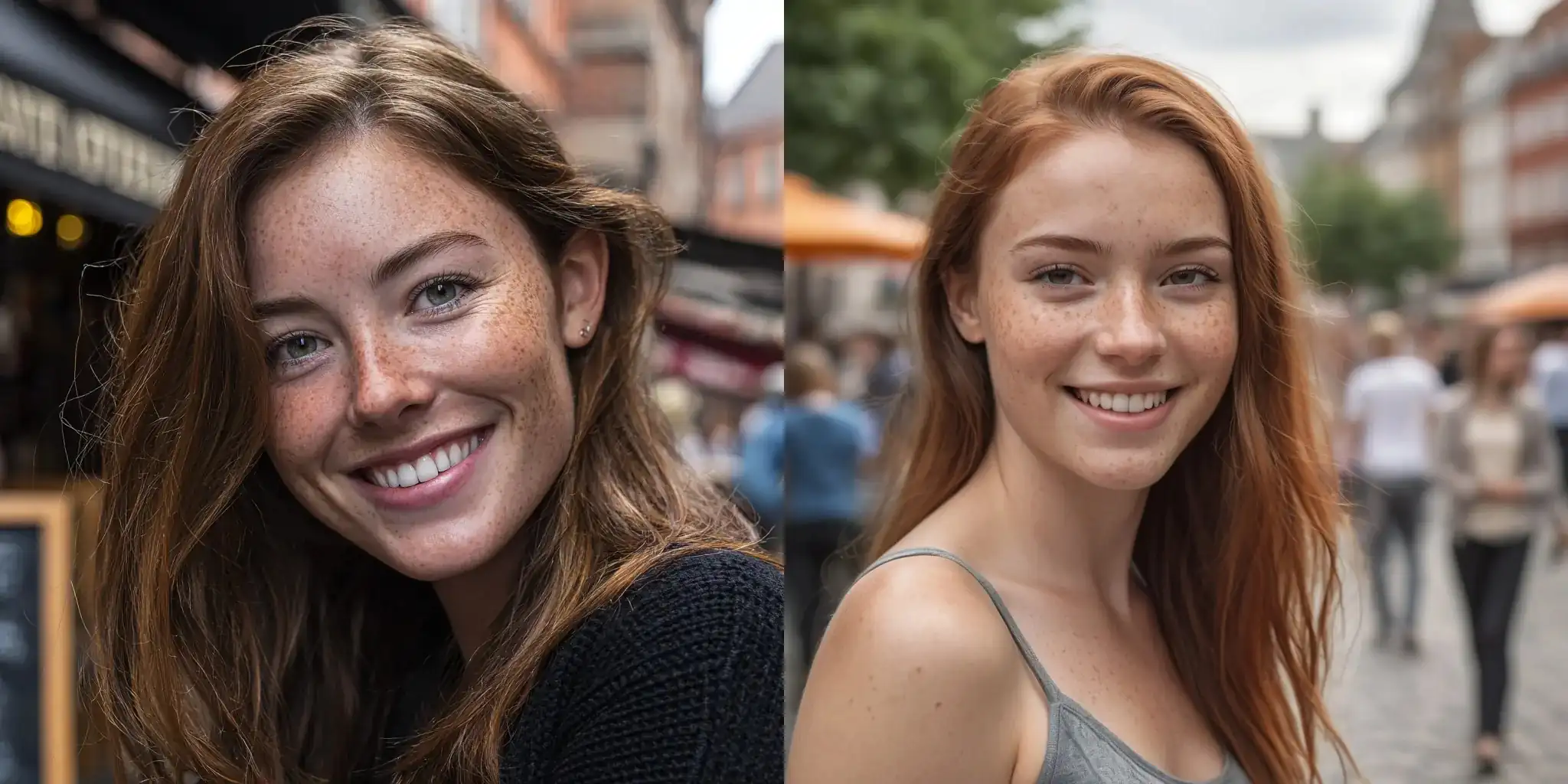
Chociaż grafiki wygenerowane przez Flux Kontext Max, Nano Banana czy Adobe Firefly, wciąż wyglądały estetycznie, posiadały ten dość łatwo dostrzegalny dla człowieka, ilustracyjny “charakter AI”.
Najsłabszym z modeli okazał się model DALL-E.

| Model | Ocena |
| Midjourney | 9 |
| Nano Banana | 7 |
| DALL-E 3 | 5 |
| Juggernaut XL | 9 |
| Flux Kontext Max | 8 |
| Stable Diffusion SD3 | 6 |
| Adobe Firefly | 7 |
| Ideogram | 7 |
| Leonardo AI | 6 |
| Canva AI | 5 |
| HiDream-I1 | 6 |
Test 4. Ilustracja
Kolejne zadanie polegało na wygenerowaniu ilustracji przedstawiającej kobietę w futurystycznym mieście:
As a professional designer, create a digital art illustration of a smiling young woman standing in a futuristic cyberpunk city centre, with neon lights, holographic billboards, and glowing skyscrapers in the background. She has soft freckles and smooth skin texture, enhanced with subtle cybernetic details such as glowing tattoos, augmented eyes, or sleek tech accessories. Natural and relaxed pose. The background is softly blurred to emphasize her presence. Painterly shading, high detail, vivid colors, and a cinematic shallow depth of field highlight the futuristic digital art aesthetic.
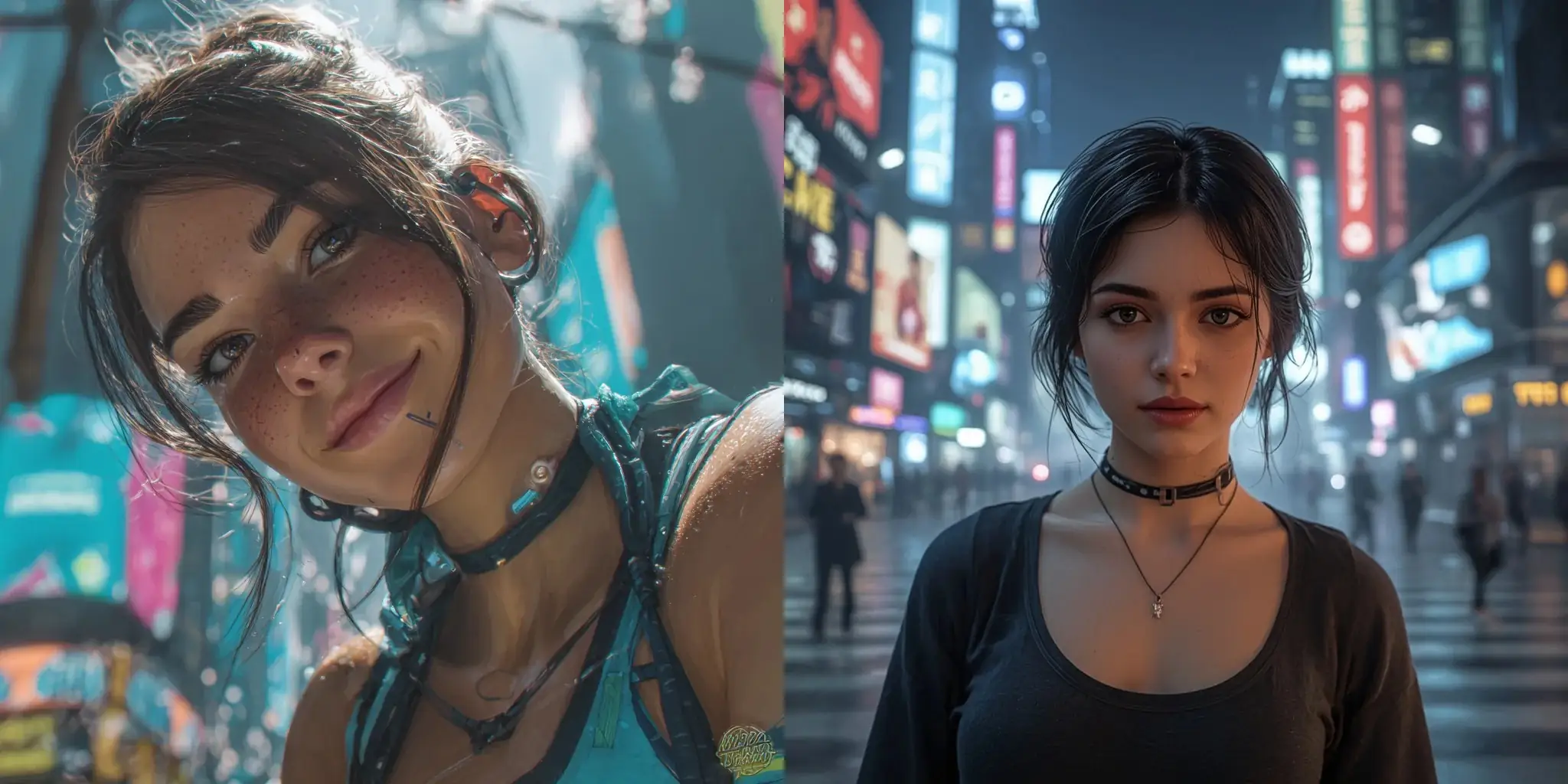
Najmniej estetyczne wyniki zwróciły HiDream-l1, którego grafika zawierała dziwne artefakty w okolicy ust oraz DALL-E 3 – stworzona przez niego ilustracja wyglądała raczej jak zlepek niepowiązanych ze sobą elementów. Firefly i Ideogram wyprodukowały grafiki, które trudno nazwać spójnymi – na każdym z nich, postać wyglądała jak wycięta z innego obrazu i wklejona na cyberpunkowe tło.

Jakością wyróżniały się obrazy od Leonardo AI oraz Midjourney, który wygrał tę konkurencję liczbą detali.
| Model | Ocena |
| Midjourney | 9 |
| Nano Banana | 6 |
| DALL-E 3 | 3 |
| Juggernaut XL | 7 |
| Flux Kontext Max | 7 |
| Stable Diffusion SD3 | 5 |
| Adobe Firefly | 5 |
| Ideogram | 5 |
| Leonardo AI | 8 |
| Canva AI | 6 |
| HiDream-I1 | 4 |
Test 5. Grafika koncepcyjna – postać
W przedostatnim etapie prompt zakłada stworzenie grafiki koncepcyjnej, przedstawiającą postać do gry komputerowej:
As a concept artist, create highly detailed concept art of a cyberpunk female character for a video game. Full-body turnaround sheet showing the character from front view, back view, left profile, and right profile. Futuristic outfit with neon accents, cybernetic implants, and sleek armor pieces, blending teal, orange, white, and black color palette. Sharp linework, intricate mechanical details, glowing elements, and high-tech accessories. Stylized character sheet format on a clean background, professional concept art style, symmetrical alignment of views – designed for character design reference.

Zgodnie z poleceniami, postać powinna być widoczna z przodu, z tyłu oraz z profili. Z tym zadaniem jako jedyny poradził sobie Midjourney. Output od Flux Kontext Max, Juggernaut XL oraz Leonardo omijał jeden z widoków, dwukrotnie przedstawiając przód czy profil postaci.

Największy przegrany to tutaj DALL-E, którego grafika (widoczna powyżej) była nie tylko mało estetyczna, ale i chaotyczna – model przedstawił jeden z profili postaci… z odwróconą głową.
| Model | Ocena |
| Midjourney | 8 |
| Nano Banana | 6 |
| DALL-E 3 | 3 |
| Juggernaut XL | 6 |
| Flux Kontext Max | 6 |
| Stable Diffusion SD3 | 4 |
| Adobe Firefly | 6 |
| Ideogram | 5 |
| Leonardo AI | 5 |
| Canva AI | 4 |
| HiDream-I1 | 7 |
Test 6. Grafika koncepcyjna – lokacja
W ostatnim zadaniu, modele wygenerowały grafikę koncepcyjną przedstawiającą przykładową lokację z gry fantasy:
As a concept artist, create highly detailed concept art of a medieval fantasy chamber for a video game. The location is filled with magical artifacts and alchemy tools. Stone walls with glowing runes, shelves stacked with books, and bubbling elixirs in glass flasks. A wooden alchemist’s table covered with parchment, candles, potions, and ancient scrolls. Soft torchlight mixed with eerie magical glow in teal, orange, white, and black tones. Epic, atmospheric fantasy environment design, rich textures, cinematic lighting, highly detailed interior illustration, professional game concept art style

Tu ponownie wygrał Midjourney, generując obraz, który zignorował część poleceń (runy na ścianach, półki z książkami), jednak wygenerował scenę z dobrą widocznością, która nie wygląda jak losowa ilustracja, a grafika koncepcyjna lokacji, która ma zostać przeniesiona w świat wirtualny. Do tego efektu zbliżyła się także Canva AI.
| Model | Ocena |
| Midjourney | 8 |
| Nano Banana | 7 |
| DALL-E 3 | 5 |
| Juggernaut XL | 6 |
| Flux Kontext Max | 6 |
| Stable Diffusion SD3 | 5 |
| Adobe Firefly | 5 |
| Ideogram | 4 |
| Leonardo AI | 6 |
| Canva AI | 7 |
| HiDream-I1 | 7 |
Prawa autorskie do treści, prywatność i generatory obrazów AI za darmo
W powyższych testach, modele z rankingu w większości przypadków generowały gotowy obraz w czasie między 10-25 sekund (wyjątkiem bywał niekiedy Adobe Firefly, przekraczając 20 sekund). Tworzone przez nie treści mogą też być wykorzystywane komercyjnie (jeśli jesteśmy subskrybentami danej platformy) – z zaznaczeniem, że grafik tworzonych przez AI nie można objąć prawem autorskim.
Kolejna istotna kwestia to prywatność.
W przypadku większości modeli, oznacza ona niedostępność generowanych grafik dla innych użytkowników platformy. Więcej wymagać nie można, ponieważ każdy obraz jest generowany na serwerach firmy.
Jeśli jednak potrzebujemy absolutnej prywatności, jedynym rozwiązaniem jest lokalne hostowanie modeli. Wśród najtańszych kart graficznych pozwalających na pracę z modelami Open Source z tego rankingu znajdziemy GeForce RTX 5060 Ti z 16GB pamięci VRAM, której cena oscyluje w okolicach 2000 zł. By osiągnąć najwyższą jakość obrazów przy jak najkrótszym czasie ich generowania, powinniśmy jednak sięgnąć po karty z serii 5090 lub lepsze, co będzie oznaczać koszt kilkunastu tysięcy złotych.
Podsumowanie pierwszej części testów
Najlepsze wyniki osiągnął Midjourney, a tuż za nim znalazł się Flux Kontext Max. Podium zamknął wychwalany wszędzie Nano Banana od Google’a i już to może wyglądać na małą niespodziankę.
Zestawienie, na miejscu 11., zamyka jednak niespodzianka największa – DALL-E 3 od OpenAI, który został pobity przez trzy modele Open Source i jako jedyny osiągnął wynik niższy, niż 4.5.
- Midjourney: 7.5
- Flux Kontext Max: 7.3
- Nano Banana: 6.7
Miejsca na podium nie są jednak ostateczne, ponieważ modele Flux Kontext Max i Nano Banana są tu jedynymi narzędziami stworzonymi z myślą o kompleksowej edycji grafik, próbując być odpowiednikami Photoshopa w świecie AI. Tym samym czeka je jeszcze jedna seria testów, w której stoczą walkę o 1 punkt, wyłaniający najlepszy (bo najbardziej uniwersalny) model tego rankingu.
Flux Kontext Max vs Gemini 2.5 Flash Image (Nano Banana): porównanie dwóch potężnych narzędzi do edycji grafik
Test 1. Rozszerzenie zdjęcia i modyfikacja wyglądu postaci
Na początku, każdy model otrzyma zdjęcie kobiety wygenerowane przez MidJourney oraz logo naszego portalu.
Jego zadaniem będzie oddalenie widocznej na oryginalnej fotografii kobiety od aparatu, zmiana scenerii, w której się znajduje, umieszczenie tatuażu na jej ręce oraz ubranie jej w czarny t-shirt z nadrukowanym logo i czapkę z logiem bitcoina. W tym celu skorzystamy z promptu poniżej:
The woman in the image is staying further from the camera and showing a peace sign with her fingers. She has a black and white bitcoin tattoo on her forearm; she is wearing a black t-shirt imprinted with a provided logo and cap with Bitcoin logo. The logos are clearly visible. natural skin lighting, people and restaurants in the background, realistic anatomy, natural pose, shallow depth of field, 85mm lens photography
Pod względem jakości oba narzędzia poradziły sobie nieźle, ale tę konkurencję nieznacznie wygrywa Nano Banana. Dokładnie zachował prompt, umieszczając na zdjęciu dokładnie to, czego potrzebowaliśmy – czapkę z logo bitcoina, tatuaż oraz koszulkę z logiem portalu.

Flux Kontext Max wygenerował postać, której postawa i wyraz twarzy wyglądają, przynajmniej na mój gust, nieco naturalniej i “mniej marketingowo”. Jeśli faktycznie tak jest, model zepsuł ten efekt, nie spełniając warunków dot. tatuażu (2-3 przypadkowe tatuaże z losowych znaków) i loga na czapce (logo portalu, zamiast loga BTC).
| Model | Punkty |
| Nano Banana | 1 |
| Flux Kontext Max | 0 |
Test 2. Dodatkowa postać
W kolejnym kroku najlepsze zdjęcie z poprzedniego zadania (od Nano Banana) i spróbujemy je rozbudować, dodając do niego kobietę wygenerowaną przez Juggernaut XL.
Two women are standing side by side. Both women are clearly visible. no cropping. Natural skin lighting, realistic anatomy, natural pose, shallow depth of field, 85mm lens photography
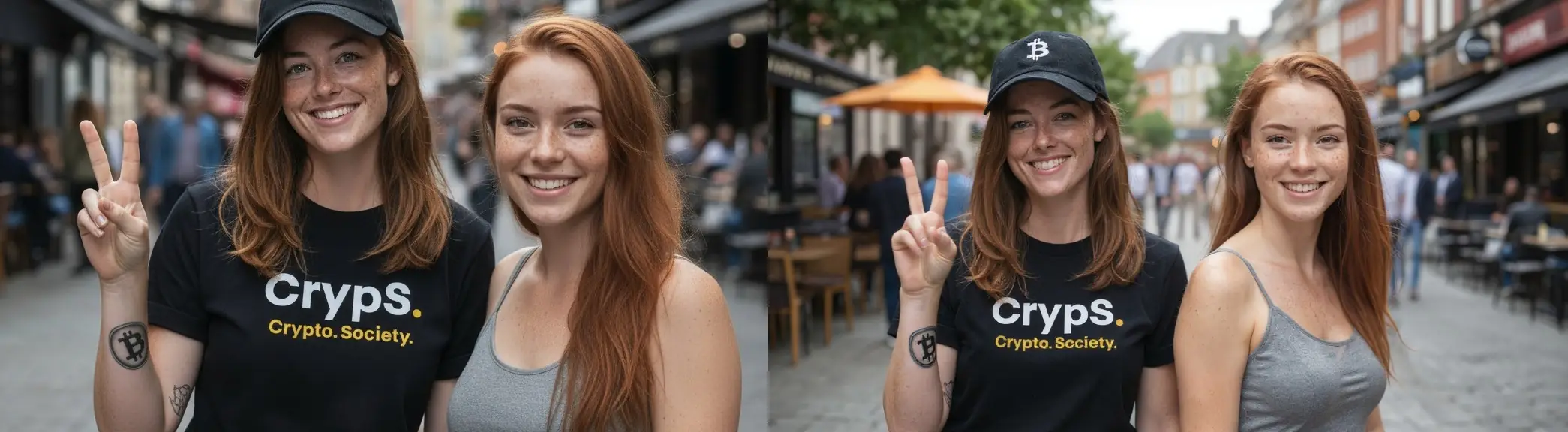
W tym przypadku lepszy wynik osiągnął Flux Kontext Max, ponieważ w przeciwieństwie do Nano Banana, zachował prompt (nie przyciął postaci).
Teraz, kobieta po prawej zostanie ubrana w biały t-shirt z napisem i okulary przeciwsłoneczne:
The woman on the right wears sunglasses and a white t-shirt with the black text saying: “THE FUTURE IS NOW, OLD MAN…”. Do not modify the clothing of the woman on the left. Natural skin lighting, realistic anatomy, natural pose, shallow depth of field, 85mm lens photography
Na tym etapie wszystko wraca do normy – ponownie wygrywa Nano Banana. Kontext Max nie poradził sobie z zadaniem, podmieniając postać po lewej stronie.
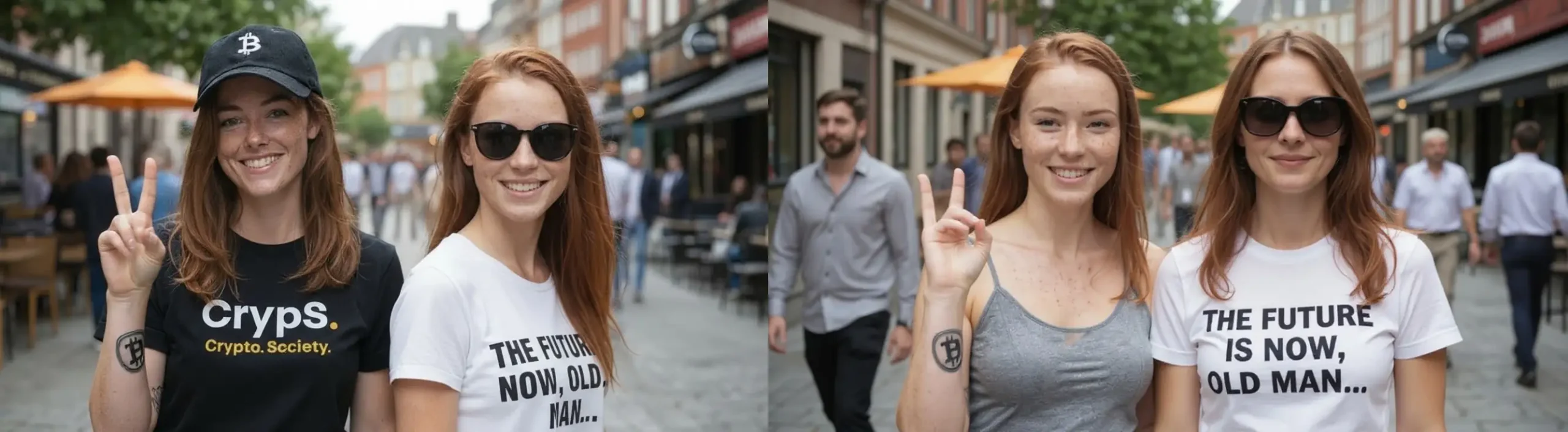
Za całość testu model Google’a otrzymuje 1 punkt, a Flux Kontext – tylko 0.5, ponieważ jego przewaga w pierwszym zadaniu była bardzo niewielka.
| Model | Punkty |
| Nano Banana | 2 |
| Flux Kontext Max | 0.5 |
Test 3. Stylizacja a’la Studio Ghibli
Ostatni, krótki test dotyczący postaci będzie polegał na zmianie ostatniego zdjęcia w ilustrację w popularnym w internecie stylu Studio Ghibli:
Remake this image in the Studio Ghibli art style, preserving the original composition, lighting, and character design. Pastel colors, warm natural light, cinematic mood.

Kontext Max miał niewielki problem z odczytaniem tekstu z białej koszulki (co jest zrozumiałe), jednak wykonał to, co do niego należało, dlatego otrzymuje 1 punkt. Z kolei Nano Banana nie zrobił ze zdjęciem nic, prócz lekkiego podkręcenia kolorów. Niektóre opinie z Reddita na temat tego modelu mówią, że nadaje się on przede wszystkim do przetwarzania realistycznych fotografii, nie najlepiej radząc sobie ze stylizowaniem zdjęć na ilustracje. Testy zdają się to potwierdzać.
| Model | Punkty |
| Nano Banana | 2 |
| Flux Kontext Max | 1.5 |
Test 4. Grafika e-commerce
Ostatnia z prób polega na stworzeniu dwóch pełnych grafik e-commerce, uwzględniających fikcyjny produkt ze zdjęcia wygenerowanego wcześniej przez Nano Banana. W tym przypadku spróbujemy stworzyć gotową grafikę za jednym zamachem, dlatego prompt będzie dość długi i bardziej skomplikowany:
As a professional graphic designer, create a high-quality commercial-style illustration. Place the logo on the soda can, rotated 45 degrees, seamlessly blended with the can’s surface for a realistic look. The logo should be large, covering almost the whole height of the can. Add small black, repeating text saying “Crypto Society on the yellow circle on top of the can. Add small cryptocurrency symbols scattered across the can. Make the can appear slightly frosty for a refreshing effect, and position it on a bed of ice. Surround the can with physical Bitcoin coins placed on the ice. In the top-left corner, include the text: ‘YOUR DAILY DOSE OF NEWS’. The word ‘NEWS’ should be yellow, matching the yellow accents of the can, while the other words should be white. In the distant background, add subtle neon-purple line charts with a soft glow.
Chociaż grafiki od Kontext Max nie są najgorsze, model miał problemy z tekstem, detalami, zachowaniem oryginalnego wyglądu produktu oraz w pierwszym przypadku – z logiem (logo BTC zamiast loga portalu).

Tymczasem Nano Banana po raz kolejny pokazał, kto tu rządzi. Nie dość, że spełnił zdecydowaną większość warunków promptu, to wygenerowane przez niego treści wyglądają lepiej. Gdzieś tutaj zaciera się granica między “contentem AI”, a ilustracją stworzoną przez grafika.
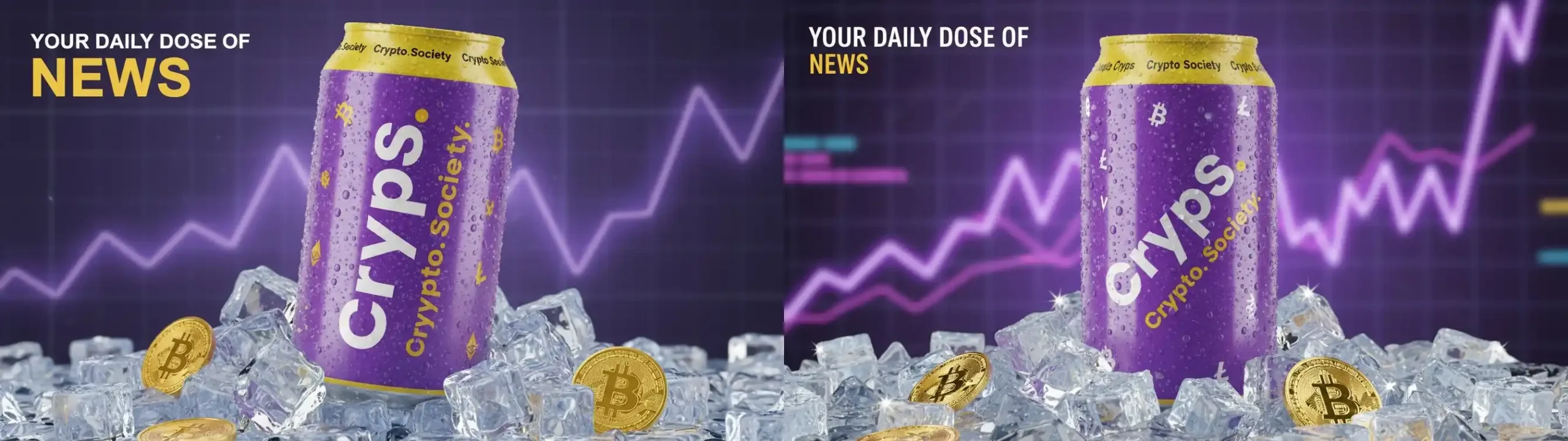
Na koniec, czas na zmodyfikowany, trudniejszy wariant promptu, w którym przedstawiona na grafice puszka ma unosić się w realistycznej, pomarańczowej cieczy. Wcześniejsze polecenie rozwiniemy o:
… position the can floating or partially submerged in a thick, glossy orange liquid, resembling a dense syrup or melted orange glass. The liquid should have realistic reflections and a rich, saturated texture.Within the liquid, include a few physical Bitcoin coins, colored metallic purple to match the purple accents of the can. The coins should be partially visible, some floating, some slightly below the surface, interacting with the liquid realistically.

Jak widać wyżej, Flux Kontext Max dobrze poradził sobie z realizmem cieczy, jednak przegrał w podobny sposób – nieumiejętnością zachowania promptu (brak napisów na żółtej części puszki) oraz estetyką. To, co dostaliśmy od Nano Banana, mimo wad (symbole klasycznych walut na puszce, żółta litera “D”), znowu – prezentuje się po prostu lepiej.
| Model | Punkty |
| Nano Banana | 3 |
| Flux Kontext Max | 1.5 |
Ostatecznie wygrywa Nano Banana, który zyskuje 1 punkt w ogólnym rankingu i z oceną 7.7 zostaje zwycięzcą całego zestawienia.
Ranking 2025: Top 11 generatorów obrazów AI
Poniżej znajdziesz nasz subiektywny ranking najlepszy modeli. Jeśli po przebrnięciu przez artykuł stwierdzasz, że w Twoim przypadku warto byłoby korzystać z kilku modeli AI, najlepszym rozwiązaniem będzie skorzystanie z platformy OpenArt, gdzie w zamian za niewielką kwotę możesz korzystać z nich wszystkich zamiennie. Sprawdź aktualny cennik na openart.ai.
1. Gemini 2.5 Flash Image (Nano Banana) | jakość: 7.7
🟢 Mocne strony: edycja grafik, tworzenie kolaży z różnych obrazów, grafika e-commerce, prosty interfejs, uniwersalny
🔴 Słabe strony: niekiedy nie radzi sobie z tekstem
Nano-Banana to potoczne określenie dla modelu Gemini 2.5 Flash Image od Google’a. Chociaż oferuje on opcję generowania pojedynczych zdjęć, nie jest kolejnym modelem text-to-image, a raczej narzędziem edytorskim, zaprojektowanym tak, by dokonywać lokalnych zmian w obrazach, czy syntezy różnych grafik dostarczonych przez użytkownika, zachowując przy tym spójność zawartych na nich elementów.
W przypadku API Google’a, za korzystanie z modelu musimy zapłacić 30$ za 1 000 000 tokenów, co przekłada się na cenę ok. 0.039$ za jeden obraz.
- Cena w OpenArt (za zdjęcie): 15 kredytów
- Wersja darmowa: TAK. Użytkownicy AI Studio mogą korzystać z modelu za darmo z pewnymi limitami.
- Prawa do wykorzystania komercyjnego: TAK (jednak generowane obrazy posiadają niewidoczny znak cyfrowy SynthID)
- Prywatność: grafiki niewidoczne dla innych użytkowników
- Integracje / API: dostęp przez Gemini API, Google AI Studio, a także przez platformę Vertex AI w rozwiązaniach enterprise.
2. Midjourney | jakość: 7.5
🟢 Mocne strony: realistyczne grafiki, ilustracje, detale, jakość
🔴 Słabe strony: słabiej radzi sobie z tekstem, w przypadku wersji z Discorda – interfejs mało intuicyjny dla początkujących, prywatność – bez planu Pro i Stealth Mode inni użytkownicy widzą nasze grafiki
Midjourney to jeden z najpopularniejszych modeli tekst –> obraz, dostępny przez interfejs Discord oraz sekcję Create na stronie Midjourney. W przypadku Discorda, użytkownik wpisuje prompt z komendą /imagine na początku, a bot zwraca kilka wariantów grafiki, które można skalować lub tworzyć ich wariacje. Narzędzie cechuje się stylistyczną spójnością, dbałością o detale i świetnie sprawdza się w przypadku generowania zarówno ilustracji, jak i realistycznych zdjęć.
Model dostępny jest w planach subskrypcyjnych, które różnią się m.in. dostępnym Fast GPU Time – liczbą godzin, które możemy wykorzystać do szybkiego generowania treści:
- Basic: 10$ miesięcznie (8$ w planie rocznym)
- Standard: 30$ miesięcznie (24$ w planie rocznym)
- Pro: 60$ miesięcznie (48$ w planie rocznym)
- Mega: 120$ miesięcznie (96$ w planie rocznym)
- Niedostępny w OpenArt
- Wersja darmowa: NIE
- Prawa do wykorzystania komercyjnego: TAK
- Prywatność: grafiki niewidoczne dla innych użytkowników w Stealth Mode (dostępnym od planu Pro)
- Integracje / API: brak oficjalnego API
3. Flux.1 Kontext Max | jakość: 7.3
🟢 Mocne strony: edycja grafik, generowanie minimalistycznych grafik, stylizacja zdjęć, uniwersalny
🔴 Słabe strony: niekiedy nie radzi sobie z tekstem,
To model stworzony przez Black Forest Labs do generowania i edycji obrazów z uwzględnieniem kontekstu („Kontext”). Wyróżnia się zdolnością do lokalnych edycji (inpainting), przy zachowaniu spójności danej sceny, co czyni z niego bezpośredniego konkurenta Nano-Banana.
Kontext Max jest częścią oferty Flux AI, gdzie mamy możliwość wykupienia jednego z trzech planów (nie uwzględniając planu Enterprise wymagającego bezpośredniego kontaktu z firmą):
- Starter: 15$ miesięcznie
- Pro: 39$ miesięcznie
- Teams: 49$ miesięcznie
- Cena w OpenArt (za zdjęcie): 10 kredytów
- Wersja darmowa: TAK – wersja trial
- Prawa do wykorzystania komercyjnego: TAK
- Prywatność: grafiki niewidoczne dla innych użytkowników
- Integracje / API: API Flux AI
4. Leonardo AI (Lucid Origin & Lucid Realism) | jakość: 6.2
🟢 Mocne strony: ilustracja
🔴 Słabe strony: w wersji darmowej inni użytkownicy widzą nasze zdjęcia,
Leonardo AI oferuje dwa modele, w zależności od potrzeb użytkownika:
- Lucid Origin: przeznaczony do generowania różnorodnych, stylizowanych obrazów.
- Lucid Realism: skoncentrowany na tworzeniu realistycznych obrazów.
Korzystanie z nich możliwe jest w trzech planach subskrypcyjnych (nie uwzględniając planu Leonardo for Teams, przeznaczonego dla firm):
- Apprentice: 12$ na miesiąc
- Artisan Unlimited: 30$ na miesiąc
- Maestro Unlimited: 60$ na miesiąc
W każdym z tych planów to użytkownik decyduje, komu udostępnić stworzone obrazy, podczas gdy w wersji darmowej, wszystkie wygenerowane przez niego treści są publiczne.
- Niedostępny w OpenArt
- Wersja darmowa: TAK
- Prawa do wykorzystania komercyjnego: TAK –
- Prywatność: grafiki niewidoczne dla innych użytkowników w planach płatnych
- Integracje / API: Leonardo oferuje interfejs webowy, integracje platform (np. pluginy) oraz możliwość użycia generacji w aplikacjach, choć dostęp do pełnego API może być ograniczony do planów wyższych.
5. Ideogram v3 | jakość: 6
🟢 Mocne strony: świetny do generowania grafik z tekstem oraz tworzenia bannerów i grafik e-commerce
🔴 Słabe strony: raczej nie jest wielozadaniowy
Ideogram to zaawansowany model text-to-image, zaprojektowany z myślą o generowaniu obrazów, które zawierają czytelny i estetyczny tekst. Potwierdziliśmy to w testach, gdzie Ideogram v3 okazał się niezastąpiony w przypadku kombinacji grafika + tekst. Najnowsza wersja 3.0 wprowadza dodatkowe ulepszenia w zakresie realizmu generowanych grafik oraz ich zgodności z poleceniami użytkownika. Model oferuje różne tryby generacji, takie jak Turbo, Balanced i Quality, umożliwiając wybór między szybkością, a jakością obrazów.
Narzędzie dostępne jest w planach:
- Basic: 7$ miesięcznie
- Plus: 15$ miesięcznie
- Pro: 42$ miesięcznie
- Cena w OpenArt (za zdjęcie): 25 kredytów
- Wersja darmowa: TAK
- Prawa do wykorzystania komercyjnego: TAK
- Prywatność: grafiki niewidoczne dla innych użytkowników tylko w planach Plus i Pro
- Integracje / API: Ideogram API,
6. Canva AI | jakość: 6
🟢 Mocne strony: wsparcie dla osób korzystających z Canva
🔴 Słabe strony: uciążliwy eksport grafik w interfejsie Canva, przeciętny w porównaniu do konkurencji
Canva AI to nie tyle osobny model przeznaczony dla użytkowników skupionych na generowaniu grafik, ile rozszerzenie funkcji sztucznej inteligencji w ramach ekosystemu platformy Canva. Generowanie obrazów i edycja elementów graficznych odbywają się tu bezpośrednio w jej środowisku, dlatego jest to opcja przede wszystkim dla tych, którzy mają zamiar korzystać z Canva jako narzędzia do projektowania graficznego, traktując model GenAI jako pomoc w pracy.
Narzędzie dostępne jest w planach:
- Canva Pro: 50zł za miesiąc
- Canva Teams: minimalnie 114 zł miesięcznie – 38 zł od osoby, plan musi obejmować minimum 3 użytkowników,
- Niedostępny w OpenArt
- Wersja darmowa: TAK
- Prawa do wykorzystania komercyjnego: TAK
- Prywatność: projekty mogą być prywatne lub współdzielone
- Integracje / API: Canva API
7. Adobe Firefly | jakość: 5.8
🟢 Mocne strony: integracja z innymi narzędziami od Adobe, trenowany na licencjonowanych treściach
🔴 Słabe strony: w porównaniu do najlepszych modeli – raczej przeciętna jakość
Firefly to model generatywny od Adobe, stworzony jako narzędzie wspierające kreatywną pracę grafików w ramach ekosystemu Adobe Creative Cloud. Jest więc ściśle zintegrowany z popularnymi aplikacjami ze stajni firmy, takimi jak Photoshop, Illustrator czy Express, co pozwala na generowanie i edycję obrazów bezpośrednio w miejscu pracy.
Twórcy położyli szczególny nacisk na prawa autorskie – Adobe podkreśla, że Firefly został wytrenowany na treściach z licencjonowanych źródeł i tych znajdujących się w domenie publicznej, co daje użytkownikom większą pewność co do zgodności z prawem przy komercyjnym wykorzystaniu wygenerowanych treści. Jest to jednak miecz obosieczny, ponieważ chociaż bezpieczny w użyciu dla profesjonalistów, Firefly jest modelem bardziej “konserwatywnym” niż produkty konkurencji.
Do modelu można uzyskać dostęp w ramach subskrypcji Adobe Creative Cloud Pro za 69.99$ miesięcznie (obejmującym inne narzędzia od Adobe, takie jak PS) lub w planach skupiających się tylko na nim:
- Firefly Standard: 9.99$ za miesiąc
- Firefly Pro: 19.99$ za miesiąc
- Firefly Premium: 199.99$ za miesiąc
- Niedostępny w OpenArt
- Wersja darmowa: TAK
- Prawa do wykorzystania komercyjnego: TAK
- Prywatność: grafiki niewidoczne dla innych użytkowników
- Integracje / API: bezpośrednie włączenie do narzędzi Adobe (Photoshop, Illustrator itd.) oraz Adobe Firefly API
8. Juggernaut XL (open source) | jakość: 5.7
🟢 Mocne strony: dobry do generowania realistycznych zdjęć ludzi
🔴 Słabe strony: większość zadań poza generowaniem zdjęć ludzi,
Juggernaut XL to model oparty na Stable Diffusion XL zoptymalizowany pod kątem wysokiej rozdzielczości i detali, co czyni go jednym z lepszych modeli do generowania realistycznych zdjęć. Jest dostępny na licencji Open Source, dlatego możemy przetestować go za darmo korzystając z Google Collab np. przez interfejs Fooocus (aż do limitów GPU Google Collab) lub korzystać z niego bez opłat na własnym GPU.
Jeśli nie dysponujemy odpowiednim sprzętem, model dostępny jest na platformie OpenArt w cenie 1 kredytu za obraz, tak więc plan Essential za 14$ pozwoli nam na wygenerowanie 4000 zdjęć, co daje koszt 0.0035$/zdjęcie.
- Cena w OpenArt (za zdjęcie): 1 kredyt
- Wersja darmowa: TAK – np. z limitami GPU na Google Collab.
- Prawa do wykorzystania komercyjnego: TAK (lub zależne od regulaminu platformy hostującej)
- Prywatność: TAK – w przypadku hostowania lokalnego
- Integracje / API: integracja przez HuggingFace
9. HiDream l1 (Open Source) | jakość: 5.7
🟢 Mocne strony: jak na model Open Source – niekiedy generuje niezłej jakości realistyczne zdjęcia ludzi i ilustracje
🔴 Słabe strony: nie radzi sobie z grafikami z tekstem
L1 to podstawowy model z rodziny HiDream, generujący obrazy w różnych stylach, takich jak fotorealizm, sztuka czy kreskówki, kładący nacisk na spełnianie warunków promptu. To narzędzie Open Source możliwe do uruchomienia lokalnego lub dostępne na platformach hostujących.
- Cena w OpenArt (za zdjęcie): 5 kredytów
- Wersja darmowa: TAK
- Prawa do wykorzystania komercyjnego: TAK (lub zależne od regulaminu platformy hostującej)
- Prywatność: TAK – w przypadku hostowania lokalnego
- Integracje / API: brak
10. Stable Diffusion SD3 (3.0) (Open Source) | jakość: 4.7
🟢 Mocne strony: realizm
🔴 Słabe strony: niekiedy nie radzi sobie z tekstem
Stable Diffusion SD3 od Stability AI to jeden z najpopularniejszych, obok starszego SDXL, modeli text-to-image dostępnych Open Source. Dzięki wolnemu dostępowi do kodu, projekt jest w dużej mierze wspierany przez społeczność, tworzącą do niego rozszerzenia czy własne warianty (takie, jak Juggernaut XL, oparty na SDXL).
Użytkownicy mogą uruchamiać model lokalnie (na własnym GPU) lub korzystać z niego poprzez platformy hostujące.
- Cena w OpenArt (za zdjęcie): 5 kredytów
- Wersja darmowa: TAK
- Prawa do wykorzystania komercyjnego: TAK (lub zależne od regulaminu platformy hostującej)
- Prywatność: TAK – w przypadku hostowania lokalnego
- Integracje / API: szeroki ekosystem uwzględniający m.in. interfejsy użytkownika takie jak AUTOMATIC1111
11. DALL·E 3 | jakość: 4.2
🟢 Mocne strony: prosty interfejs
🔴 Słabe strony: niekiedy – grafika z tekstem, niska jakość ilustracji,
Największym plusem DALL-E 3 jest prosty interfejs. Model jest zintegrowany z LLM’em ChatGPT i dostępny dla użytkowników korzystających z planów Plus (23e za miesiąc) i Pro (229e za miesiąc). Względem innych modeli z zestawienia, pozostawia jednak sporo do życzenia pod względem jakości generowanych obrazów.
- Cena w OpenArt (za zdjęcie): 1 kredyt
- Wersja darmowa: TAK – 2 obrazy dziennie dla użytkowników ChatGPT bez płatnego planu
- Prawa do wykorzystania komercyjnego: TAK
- Prywatność: grafiki niewidoczne dla innych użytkowników
- Integracje / API: oficjalne API OpenAI
FAQ
W wersjach płatnych, narzędzia AI do generowania grafik dają użytkownikowi prawo do ich komercyjnego użycia. Uzyskanie do nich praw autorskich może być jednak niemożliwe.
Najlepszym modelem AI do generowania fotorealistycznych portretów był w naszym rankingu Midjourney.
W przypadku planów subskrypcyjnych – do generowania grafik z AI wystarczy dostęp do internetu. Jeśli jednak chcemy generować grafiki lokalnie – potrzebujemy mocnej karty graficznej.
By uniknąć problemów prawnych, dane, na których trenowano dany model, musiały być pozyskane legalnie.
Użytkownik korzystający z modeli nie posiada także praw autorskich do wygenerowanych obrazów – jedynie prawo do użytku komercyjnego.
Generowane przez niego grafiki nie mogą także zawierać elementów chronionych prawem autorskim. Największymi problemami etycznymi są z kolei dezinformacja i wykorzystanie wizerunków osób bez ich zgody.
Tak – istnieją modele stworzone w tym celu. Na edycję istniejących zdjęć (tzw. inpainting) pozwalają m.in. Gemini 2.5 Flash Image (Nano Banana), Flux.1 Kontext Max i Adobe Firefly.
Narzędzia AI z prostym interfejsem, przyjaznym początkującym, to m.in. Nano Banana, Leonardo AI, DALL-E 3 i Midjourney (w wersji przeglądarkowej).
Jednym z najlepszych, darmowych generatorów grafik AI jest Stable Diffusion XL. Warto wspomnieć też o bazującym na nim modelu Juggernaut XL, przeznaczonym do generowania realistycznych obrazów.
W generowaniu grafik uwzględniających tekst – takich jak bannery czy obrazki na social media, najlepiej sprawdza się Ideogram v3.
Śledź CrypS. w Google News. Czytaj najważniejsze wiadomości bezpośrednio w Google! Obserwuj ->
Zajrzyj na nasz telegram i dołącz do Crypto. Society. Dołącz ->








