

Za uniwersalny język technologii uważa się angielski, dlatego to właśnie z nim sztuczna inteligencja powinna radzić sobie najlepiej. Przynajmniej teoretycznie, ponieważ świeże badania przynoszą zaskakujące wieści – najskuteczniejszym w komunikacji z AI okazał się język polski.
- Wg. wyników badania przeprowadzonego m.in. przez Microsoft najefektywniejszy w pracy z AI okazał się język polski – wyprzedzając angielski, który zajął dopiero 6. miejsce.
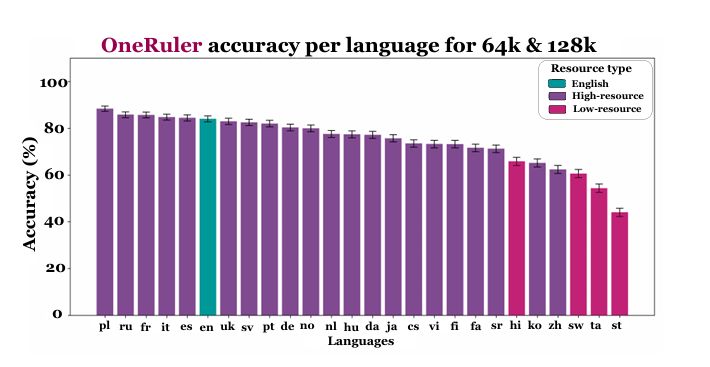
- Prompt w języku polskim świetnie sprawdzał się w testach, w których model musiał pracować z długim kontekstem, gdzie badany tekst obejmował 64 i 128 tysięcy tokenów.
Polszczyzna najskuteczniejsza w komunikacji z AI. Pokonała 26 innych języków
Badanie pt. “One ruler to measure them all: Benchmarking multilingual long-context language models” opublikowane przez naukowców z University of Maryland i Microsoftu pokazuje, że złożoność języka polskiego, która czyniła go jednym z najtrudniejszych na świecie, może być kluczem do precyzji wyrazu, której AI potrzebuje do rozwiązywania najbardziej skomplikowanych zadań.
W ramach benchmarku o nazwie OneRuler, polski osiągnął skuteczność na poziomie 88%, co jest wynikiem, który zapewnił mu pierwsze miejsce wśród 26 analizowanych języków.
Benchmarking multilingual long-context language models
Angielski, jako fundament, na którym trenowana jest większość modeli językowych, zajął dopiero pozycję szóstą z wynikiem niespełna 84%.
Zespół badawczy, w skład którego weszli Yekyung Kim, Jenna Russell, Marzena Karpińska i Mohit Iyyer, poddał testom grupę modeli językowych, w tym Gemini 1.5 Flash od Google’a czy zaawansowane wersje Llama 3 i Qwen2.5.
Celem było sprawdzenie ich zdolności do pracy z tzw. długim kontekstem, liczącym do nawet 128 tysięcy tokenów (to umiejętność kluczowa w analizie prac naukowych czy streszczaniu obszernych dokumentów). LLM-y zmierzyły się z kikoma zadaniami, w tym z nowymi wariantami testu Needle-in-a-Haystack (“igła w stogu siana”), polegającym na znalezieniu konkretnej informacji w ogromnym fragmencie tekstu. W nich miały na celu np. ekstrakcję kilku informacji jednocześnie.
W jednym z nowych wariantów “igły w stogu siana” – NONE-NIAH, poszukiwana informacja celowo nie znajdowała się w kontekście. W tym przypadku zadaniem AI było przyznanie, że badany tekst nie zawiera poprawnej odpowiedzi – to test na „uczciwość” modelu i jego odporność na generowanie fałszywych informacji – tzw. halucynacji.
Język polski pokonał konkurencję mimo mniejszych zasobów
Zwycięstwo języka polskiego jest tym bardziej intrygujące, że w świecie AI jest on klasyfikowany jako język o niewielkich zasobach treningowych – nieporównywalnie mniejszych, niż te, które dostępne są w języku angielskim (jednocześnie język chiński, który często jest wykorzystywany do trenowania LLM-ów, osiągnął w testach zaledwie 62.1% skuteczności).
Jak to możliwe, że nasz rodzimy język okazał się najskuteczniejszym? Badacze nie dają jednozacznej odpowiedzi, jednak rozwiązanie może tkwić w jego skomplikowanej strukturze, zmniejszającej ryzyko dwuznaczności, które w długich i złożonych tekstach staje się dla modeli AI poważnym problemem.
Śledź CrypS. w Google News. Czytaj najważniejsze wiadomości bezpośrednio w Google! Obserwuj ->
Zajrzyj na nasz telegram i dołącz do Crypto. Society. Dołącz ->








